Creating Books Vol 5: Word Lists

Most books available on the WordCruncher Bookstore are divided several word lists. This is to separate components of the text so that you can focus on the most important sections. For example, you're probably less likely to search within the text of footnotes unless that part is particularly interesting to you. You can switch word lists in the upper-right corner of the search window. When switching word lists, the WordWheel will update to show the words that are within that word list.
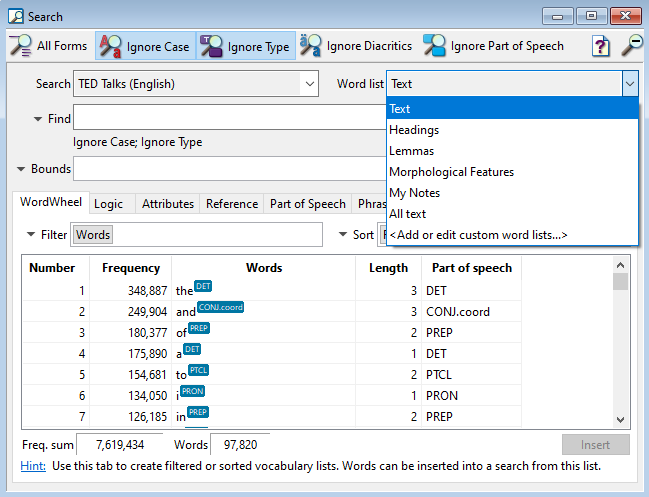
The TED Talk Corpus has these word lists:
- Text (only the text of the talks)
- Headings (titles and authors)
- Lemmas (the dictionary form and part of speech)
- Morphological features (such as tense and pronoun type)
The top word list, Text, is designated as the most important word list since it is generally the most used word list. Separating your text into different word lists is useful when you know some of the text is less useful for searching (or useful for different reasons).
Note: There are times when a user might want to search all of the wordlists at once, which is why there's an “All Text” option.
Lexicon Attributes
An individual word list can be defined with a <LEX/> tag within the <sifx> element. The order that you position the <LEX/> tags within the <sifx> determines the order within WordCruncher's search window wordlist menu. It's highly encouraged to place the most important lexicon (like “Text”) as the first tag.
The lexicon has many attributes, but these attributes are the most important.

Style Name (Required)
<LEX st="Main Text"/>
The unique name for the text style.
Language Code (Required)
<LEX id="lang"/>
The two-letter code for the language you're using. View the list of supported languages below.
Note: for most purposes, the two-letter code will be sufficient. If needed, extended region codes can also be used. For example, the code en will set the language to English, but if you wish to specify English (United Kingdom), use the code en-GB.
| Language | Code |
| Afrikaans | af-ZA |
| Albanian | sq-AL |
| Alsatian | gsw-FR |
| Amharic | am-ET |
| Arabic | ar |
| Arabic (Algeria) | ar-DZ |
| Arabic (Bahrain) | ar-BH |
| Arabic (Egypt) | ar-EG |
| Arabic (Iraq) | ar-IQ |
| Arabic (Jordan) | ar-JO |
| Arabic (Kuwait) | ar-KW |
| Arabic (Lebanon) | ar-LB |
| Arabic (Libya) | ar-LY |
| Arabic (Morocco) | ar-MA |
| Arabic (Oman) | ar-OM |
| Arabic (Qatar) | ar-QA |
| Arabic (Saudi Arabia) | ar-SA |
| Arabic (Syria) | ar-SY |
| Arabic (Tunisia) | ar-TN |
| Arabic (U.A.E.) | ar-AE |
| Arabic (Yemen) | ar-YE |
| Aramaic | arc-IL |
| Aramaic (Samaria) | arc-SY |
| Armenian | hy-AM |
| Assamese | as-IN |
| Azeri | az |
| Azeri-Latn | az-Latn-AZ |
| Azeri-Cyrl | az-Cyrl-AZ |
| Bashkir | ba-RU |
| Basque | eu-ES |
| Belarusian | be-BY |
| Bengali | bn |
| Bengali (Bangladesh) | bn-BD |
| Bengali (India) | bn-IN |
| Bosnian | bs |
| Bosnian-Latn | bs-BA |
| Bosnian-Cyrl | bs-Cyrl-BA |
| Breton | br-FR |
| Bulgarian | bg-BG |
| Catalan | ca-ES |
| Cebuano | ceb-PH |
| Cherokee | chr-US |
| Chinese-Hans | zh-Hans |
| Chinese-Hans (PRChina) | zh-CN |
| Chinese-Hans (Singapore) | zh-SG |
| Chinese-Hant | zh-Hant |
| Chinese-Hant (Hong Kong) | zh-HK |
| Chinese-Hant (Macau) | zh-MO |
| Chinese-Hant (Taiwan) | zh-TW |
| Corsican | co-FR |
| Croatian | hr |
| Croatian (Bosnia) | hr-BA |
| Croatian (Croatia) | hr-HR |
| Czech | cs-CZ |
| Danish | da-DK |
| Dari | fa-AF |
| Divehi | dv-MV |
| Dutch | nl |
| Dutch (Belgium) | nl-BE |
| Dutch (Netherlands) | nl-NL |
| Eblaite | x-eb-SY |
| English | en |
| English (Australia) | en-AU |
| English (Belize) | en-BZ |
| English (Canada) | en-CA |
| English (Caribbean) | en-VI |
| English (India) | en-IN |
| English (Ireland) | en-IE |
| English (Jamaica) | en-JM |
| English (Malaysia) | en-MY |
| English (New Zealand) | en-NZ |
| English (Philippines) | en-PH |
| English (Singapore) | en-SG |
| English (South Africa) | en-ZA |
| English (Trinidad) | en-TT |
| English (United Kingdom) | en-GB |
| English (United States) | en-US |
| English (Zimbabwe) | en-ZW |
| Estonian | et-EE |
| Faeroese | fo-FO |
| Fijian | fj-FJ |
| Filipino | fil-PH |
| Finnish | fi-FI |
| French | fr |
| French (Belgium) | fr-BE |
| French (Canada) | fr-CA |
| French (France) | fr-FR |
| French (Luxembourg) | fr-LU |
| French (Monaco) | fr-MC |
| French (Switzerland) | fr-CH |
| Frisian | fy-NL |
| Fulah (Senegal) | ff-SN |
| Galician | gl-ES |
| Georgian | ka-GE |
| German | de |
| German (Austria) | de-AT |
| German (Germany) | de-DE |
| German (Liechtenstein) | de-LI |
| German (Luxembourg) | de-LU |
| German (Switzerland) | de-CH |
| Greek | el-GR |
| Greek-Transliterated | el-x-Trns |
| Greenlandic | kl-GL |
| Gujarati | gu-IN |
| Haitian Creole | ht-HT |
| Hausa | ha-Latn-NG |
| Hawaiian | haw-US |
| Hebrew | he-IL |
| Hebrew-Transliterated | he-x-Trns |
| Hindi | hi-IN |
| Hungarian | hu-HU |
| Icelandic | is-IS |
| Igbo | ig-NG |
| Ilokano | ilo-PH |
| Inari Sami | smn-FI |
| Indonesian | id-ID |
| Inuktitut | iu |
| Inuktitut-Latn | iu-Latn-CA |
| Inuktitut-Cans | iu-Cans-CA |
| Irish | ga-IE |
| Italian | it |
| Italian (Italy) | it-IT |
| Italian (Switzerland) | it-CH |
| Japanese | ja-JP |
| K'iche | qut-GT |
| Kannada | kn-IN |
| Kashmiri | ks-IN |
| Kazak | kk-KZ |
| Kekchi | kek-GT |
| Khmer | km-KH |
| Kinyarwanda | rw-RW |
| Konkani | kok-IN |
| Korean | ko-KR |
| Kurdish | ckb |
| Kurdish (Iraq) | ku-IQ |
| Kyrgyz | ky-KG |
| Lao | lo-LA |
| Latin | la |
| Latvian | lv-LV |
| Lithuanian | lt-LT |
| Lower Sorbian | dsb-DE |
| Lule Sami | smj-NO |
| Lule Sami (Norway) | smj-NO |
| Lule Sami (Sweden) | smj-SE |
| Luxembourgish | lb-LU |
| Macedonian | mk-MK |
| Malagasy | mg-MG |
| Malay | ms |
| Malay (Brunei Darussalam) | ms-BN |
| Malay (Malaysia) | ms-MY |
| Malayalam | ml-IN |
| Maltese | mt-IN |
| Manipuri | mni |
| Maori | mi-NZ |
| Mapudungun | arn-CL |
| Marathi | mr-IN |
| Mohawk | moh-CA |
| Mongolian | mn |
| Mongolian-Cyrl | mn-MN |
| Mongolian-Mong | mn-Mong-CN |
| Nepali | ne |
| Nepali (India) | ne-IN |
| Nepali (Nepal) | ne-NP |
| Neutral | root |
| Northern Sami | se |
| Northern Sami (Finland) | se-FI |
| Northern Sami (Norway) | se-NO |
| Northern Sami (Sweden) | se-SE |
| Norwegian | no |
| Norwegian Bokmal | nb-NO |
| Norwegian Nynorsk | nn-NO |
| Occitan | oc-FR |
| Oriya | or-IN |
| Pashto | ps-AF |
| Persian | fa-IR |
| Polish | pl-PL |
| Portuguese | pt |
| Portuguese (Brazil) | pt-BR |
| Portuguese (Portugal) | pt-PT |
| Punjabi | pa-IN |
| Punjabi (India) | pa-IN |
| Punjabi (Pakistan) | pa-PK |
| Quechua | qu |
| Quechua (Bolivia) | qu-BO |
| Quechua (Ecuador) | qu-EC |
| Quechua (Peru) | qu-PE |
| Romanian | ro-RO |
| Romansh | rm-CH |
| Russian | ru-RU |
| Sakha | sah-RU |
| Samoan | sm |
| Samoan (American Samoa) | sm-AS |
| Samoan (Samoa) | sm-WS |
| Sanskrit | sa-IN |
| Scottish Gaelic | gd-GB |
| Serbian | sr |
| Serbian (Bosnia) | sr-Latn-BA |
| Serbian (Serbia) | sr-Latn-RS |
| Serbian-Cyrl (Bosnia) | sr-Cyrl-BA |
| Serbian-Cyrl (Serbia) | sr-Cyrl-RS |
| Setswana | tn |
| Setswana (Botswana) | tn-BW |
| Setswana (Sourth Africa) | tn-ZA |
| Sindhi | sd |
| Sindhi (India) | sd-IN |
| Sindhi (Afghanistan) | sd-AF |
| Sindhi (Pakistan) | sd-PK |
| Sinhala | si-LK |
| Skolt Sami | sms-FI |
| Slovak | sk-SK |
| Slovenian | sl-SI |
| Sothosa Leboa | nso-ZA |
| Southern Sami | sma-NO |
| Southern Sami (Norway) | sma-NO |
| Southern Sami (Sweden) | sma-SE |
| Spanish | es |
| Spanish (Argentina) | es-AR |
| Spanish (Bolivia) | es-BO |
| Spanish (Chile) | es-CL |
| Spanish (Colombia) | es-CO |
| Spanish (Costa Rica) | es-CR |
| Spanish (Dominican Republic) | es-DO |
| Spanish (Ecuador) | es-EC |
| Spanish (El Salvador) | es-SV |
| Spanish (Guatemala) | es-GT |
| Spanish (Honduras) | es-HN |
| Spanish (International) | es-ES |
| Spanish (Mexico) | es-MX |
| Spanish (Nicaragua) | es-NI |
| Spanish (Panama) | es-PA |
| Spanish (Paraguay) | es-PY |
| Spanish (Peru) | es-PE |
| Spanish (Puerto Rico) | es-PR |
| Spanish (Traditional) | es-x-Trad |
| Spanish (United States) | es-US |
| Spanish (Uruguay) | es-UY |
| Spanish (Venezuela) | es-VE |
| Swahili | sw-KE |
| Swedish | sv |
| Swedish (Finland) | sv-FI |
| Swedish (Sweden) | sv-SE |
| Syriac | syr-SY |
| Tagalog | tl-PH |
| Tajik | tg-Cyrl-TJ |
| Tamazight | tzm |
| Tamazight (Algeria) | tzm-Latn-DZ |
| Tamazight (Morocco) | tzm-Tfng-MA |
| Tamil | ta-IN |
| Tatar | tt-RU |
| Telugu | te-IN |
| Thai | th-TH |
| Tibetan | bo-CN |
| Tigrigna | ti |
| Tigrigna (Eritrea) | ti-ER |
| Tigrigna (Ethiopia) | ti-ET |
| Tongan | ton-TO |
| Turkish | tr-TR |
| Turkmen | tk-TM |
| Ukrainian | uk-UA |
| Upper Sorbian | wen-DE |
| Urdu | ur-PK |
| Uzbek | uz |
| Uzbek-Latn | uz-Latn-UZ |
| Uzbek-Cyrl | uz-Cyrl-UZ |
| Uyghur | ug-CN |
| Vietnamese | vi-VN |
| Welsh | cy-GB |
| Wolof | wo-SN |
| Xhosa | xh-ZA |
| Yi | ii-CN |
| Yoruba | yo-NG |
| Zulu | zu-ZA |
Break Characters (Recommended)
<LEX chrBrk="—…–"/>
List of break characters. These are characters that will break up a word during the indexing of your ETAX. This is particularly useful for characters like en-dashes or em-dashes.
No-break Characters (Recommended)
<LEX chrNobrk=":-"/>
List of no-break characters. These are characters that will not break up a word during the indexing of your ETAX. This is particularly useful for characters like colons or hyphens. For example, the text “Genesis 1:1” would keep “1:1” as one word if the colon is added to this attribute.