ETAX Documentation
This is the documentation for the XML of WordCruncher's ETAX file. You can use this to learn about different properties available for WordCruncher. If you're using the Indexer to convert file formats like TXT, RTF, and XML 2003, then an ETAX file will be generated. All the tag elements used in WordCruncher are listed and described below.
The contents of the <etax> element consist of an optional, single <sifx> element followed by a list of paragraph elements (any combination of <p> elements or <ptbl> elements) or <include/> elements. Any text contained in this element is ignored unless otherwise specified by a child element.
This is the root element for an ETAX file. The following attributes are used only one at a time for clarity, but multiple attributes can be added to the <ETAX> tag. The sample below contains an example of every attribute, but not every attribute needs to be used.
Sample <etax>
Universal ID for Book
Format:
<etax id="guid">
Sample:
<etax id="{e5956d68-c65d-4726-b4a8-c79bf4de3b4b}">
- Adds an ID to the book, which is useful when a book is being added to the official WordCruncher Bookstore. It is recommended but not necessary for personal use.
-
guidis a universally unique identifier. You can copy one by clicking on this button. The Indexer program also can generate one.
External SIFX Filename
Format:
<etax sifx="sifxPath">
Sample:
<etax sifx="sample.sifx">
- The SIFX tag contains all of the styling and document information about an individual book. See the Style Information section for more information. The <SIFX> tag can be added as the first tag within the <etax>, but it can also be an external file.
sifxPathis the relative file path for the SIFX.- For example, if your ETAX file
book.etaxis in the same directory as your SIFX filebook.sifx, then your <etax> tag should look like this:<etax sifx="book.sifx">
External ETTX Filename
Format:
<etax ettx="ettxPath">
Sample:
<etax ettx="sample.ettx">
- The ETTX tag contains information necessary to synchronize two or more books together. See the Synchronization section for more information. The <ETTX> tag can be added after the <sifx> tag, but it can also be an external file.
ettxPathis the relative file path for the ETTX.- For example, if your ETAX file
book.etaxis in the same directory as your ETTX filebook.ettx, then your <etax> tag should look like this:<etax ettx="book.ettx">
External EPOSX Filename
Format:
<etax eposx="eposxPath">
Sample:
<etax eposx="sample.eposx">
- The EPOSX tag contains information necessary to add part of speech search functionality. See the Part of Speech section for more information. The <EPOSX> tag can be added after the <sifx> tag, but it can also be an external file.
eposxPathis the relative file path for the EPOSX.- For example, if your ETAX file
book.etaxis in the same directory as your EPOSX filebook.eposx, then your <etax> tag should look like this:<etax eposx="book.eposx">
External EMTX Filename
Format:
<etax emtx="emtxPath">
Sample:
<etax emtx="sample.emtx">
- The EMTX tag contains information necessary to add a morphology search table to the search window. See the Morphology section for more information. The <EMTX> tag can be added after the <sifx> tag, but it can also be an external file.
emtxPathis the relative file path for the EMTX.- For example, if your ETAX file
book.etaxis in the same directory as your EMTX filebook.emtx, then your <etax> tag should look like this:<etax emtx="book.emtx>
Add ISBN Number to Book
Format:
<etax isbn="isbnNum">
Sample:
<etax isbn="978-1-55558-757-5">
- Adds the ISBN Number to a WordCruncher Book. (Not implemented)
isbnNumis the ISBN number for a book.
Set Expiration Date for Book
Format:
<etax exp="date">
Sample:
<etax exp="2020-12-31">
- Adds an expiration date for when the book should expire. The book will be usable through the given date.
dateshould be formatted asyyyy-mm-dd
Update Book Edition
Format:
<etax edition="editionNum">
Sample:
<etax edition="2">
- Tells the bookstore that this is a new edition of the book. This is only used when upgrading reference levels. See English Scriptures as an example.
editionNumshould be an integer.
This optional element should appear immediately after the <etax> start element and before any other element in the file. It contains additional information about the book.
| Name | Values | Description |
|---|---|---|
| title | Possible additions being considered. | Use as default when adding book to library. |
| author | ||
| publisher | ||
| copyright | ||
| printDate | ||
| revision |
This optional element must be a child of the <bookInfo> element. The text of this element will be stored in the library when the book is added to the library. This element has no attributes.
Document Styling
This <sifx> element is used to define styles like the document width and default font sizes, paragraph styles, and text styles. It is also used to define the levels in a table of contents and metadata through attributes and tagwords.
This element is optional and comes as the first element within the <etax> root element. This element has no attributes and any text contained in this element is ignored.
The Document Style Element makes global changes to a WordCruncher book. This includes default colors, margins, tabs, and more. It must be an empty element. The following attributes are used only one at a time for clarity, but multiple attributes can be added to the <DS/> tag. The sample below contains an example of every attribute, but not every attribute needs to be used.
Sample <DS/>
Default Text Color
Format:
<DS clrTxt="foregroundColor;backgroundColor"/>
Sample:
<DS clrTxt="black;white"/>
- Changes the color of text not specified in any Text Styles.
foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Search Result Hit Color
Format:
<DS clrHit="foregroundColor;backgroundColor"/>
Sample:
<DS clrHit="white;dkblue"/>
- Changes the color of the current search result hit in the Search
Results
window. Defaults to
white;dkblue. foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Nearby Search Result Hit Color
Format:
<DS clrHilite="foregroundColor;backgroundColor"/>
Sample:
<DS clrHilite="white;dkgray"/>
- Changes the color of neighboring Search Results hits that are nearby the current
search
hit result. Defaults to
white;dkgray. foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Default Hyperlink Color
Format:
<DS clrHlink="foregroundColor;backgroundColor"/>
Sample:
<DS clrHlink="27,92,118;white"/>
- Changes the color of hyperlinks not specified in any Hyperlink Styles.
foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Default Reader Bar Color
Format:
<DS clrReader="foregroundColor;backgroundColor"/>
Sample:
<DS clrReader="white;117,28,198"/>
- Changes the color of the reader bar, which is used to highlight the line of text where the cursor is located.
foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Default Reference Color
Format:
<DS clrRef="foregroundColor;backgroundColor"/>
Sample:
<DS clrRef="21,70,36;white"/>
- Changes the color of reference level text not specified in the
tStattribute of the Levels. The text of reference levels are not shown by default. They are turned on in Book Options. foregroundColoris a string of an RGB color for the font's color.backgroundColoris a string of an RGB color for the font's background color.
Default Font Size
Format:
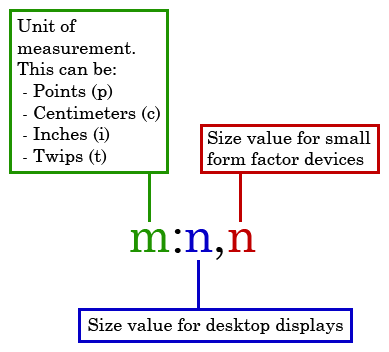
<DS tHeight="unitMeasurement:measurementSizeDesktop,[measurementSizeMobile]"/>
Sample:
<DS tHeight="p:12,11"/>
- Changes the default font size for text without a font size specified in any Text Styles .
unitMeasurementrefers to one of the screen independent units of measurement: points (p), twips (t), inches (i), or centimeters (c).measurementSizeDesktopis an integer for the font size used for desktop monitors (Windows).measurementSizeMobileis an integer for the font size used for mobile devices (iOS).
Line Width of Document
Format:
<DS lnWidth="unitMeasurement:measurementSizeDesktop,[measurementSizeMobile]"/>
Sample:
<DS lnWidth="i:12,8"/>
- Changes the maximum width of the document. If the window is smaller than
the
specified size, text will wrap according to the
wrapattribute of Paragraph Styles . unitMeasurementrefers to one of the screen independent units of measurement: points (p), twips (t), inches (i), or centimeters (c).measurementSizeDesktopis an integer for the font size used for desktop monitors (Windows).measurementSizeMobileis an integer for the font size used for mobile devices (iOS).
Change Document Left Margin
Format:
<DS mrgL="unitMeasurement:measurementSizeDesktop,[measurementSizeMobile]"/>
Sample:
<DS mrgL="i:1">
- Changes the margin width on the left side of the document.
unitMeasurementrefers to one of the screen independent units of measurement: points (p), twips (t), inches (i), or centimeters (c).measurementSizeDesktopis an integer for the font size used for desktop monitors (Windows).measurementSizeMobileis an integer for the font size used for mobile devices (iOS).- Click here to open a conversion tool between the four measurements.
Change Document Right Margin
Format:
<DS mrgR="unitMeasurement:measurementSizeDesktop,[measurementSizeMobile]"/>
Sample:
<DS mrgR="i:1">
- Changes the margin width on the right side of the document.
unitMeasurementrefers to one of the screen independent units of measurement: points (p), twips (t), inches (i), or centimeters (c).measurementSizeDesktopis an integer for the font size used for desktop monitors (Windows).measurementSizeMobileis an integer for the font size used for mobile devices (iOS).- Click here to open a conversion tool between the four measurements.
Layout Direction
Format:
<DS dir="layoutDirection"/>
Sample:
<DS dir="rtl"/>
- Determines the layout direction.
layoutDirectioncan either beltr(left-to-right) orrtl(right-to-left).- Books that are predominately right-to-left text should be set to
rtl. Individual paragraphs can still be set toltrif the text has both left-to-right and right-to-left text.
Interface Layout Direction
Format:
<DS dirCit="layoutDirection"/>
Sample:
<DS dirCit="rtl"/>
- Determines the layout direction of the citation above the Book View window.
layoutDirectioncan either beltr(left-to-right) orrtl(right-to-left).
Concordance
- Marks the document as a concordance.
-
Concordancecan either beyesorno.
Dictionary
Format:
<DS dictionary="option"/>
Sample:
<DS dictionary="yes"/>
- If this attribute exists, the document is marked as a dictionary. This is the lexicon file that the dictionary uses. Cannot be used with searchlex or thesaurus.
-
optioncan either beyesorno.
Index Style Select
Format:
<DS idxOff="style"/>
Sample:
<DS idxOff="bold"/>
- This selects styles that are not indexed by default.
-
stylecan be any combination of the following values:bold,italic,script,underline,strikeout,revised,overbar,underbar,caps,effect, andhidden.
Dictionary Entry Level
- The level type code to use as the entry level for the dictionary. Ignored if dict is not output.
Lowest Level Type
- This is the level type to be used in “lowest level” outputs (copy).
Lowest Level Search
- This is the level type to be used in “lowest level” searches.
Search Lexicon Entry Level
- The level type code to use as the entry level for the search lexicon. Ignored if searchlex is not output.
Thesaurus Entry Level
- The level type code to use as the entry level for the thesaurus. Ignored if thesaurus is not output.
Tag Window Default Paragraph Style
- The default paragraph style to be used in the Tag Window.
Ruby Text Display
Format:
<DS rtDisp="location"/>
Sample:
<DS rtDisp="top"/>
- Where to display the ruby text in relation to the base text.
-
locationcan betop,bottom, oroff.
Ruby Text Index
Format:
<DS rtIdx="option"/>
Sample:
<DS rtIdx="yes"/>
- Whether or not to index the ruby text.
-
optioncan either beyesorno.
Ruby Text Justification
Format:
<DS rtJust="option"/>
Sample:
<DS rtJust="center"/>
- Justification of the ruby text.
-
optioncan becenter,left, orright.
Ruby Text Lexicon
- Name of the lexicon this ruby text should be included in. If omitted, the ruby text is included in the same lexicon of the base text.
Ruby Text Position
Ruby Text Size
Format:
<DS rtSize="percentage"/>
Sample:
<DS rtSize="80"/>
- Size of the ruby text based on a percentage of the height of the base characters.
-
percentagecan be any integer between40and80(default is60).
Ruby Text Style
- Text style to us for the ruby text. The size specified in the text style is ignored.
Search Lexicon
Format:
<DS srchlex="option"/>
Sample:
<DS srchlex="yes"/>
- If this attribute exists, the document is marked as a search lexicon. Cannot be used with dict or thesaurus.
- If a book is marked as a thesaurus, an attribute type with the code ‘T’ and name ‘Type’ is predefined. Currently there are no values defined for this attribute type.
-
optioncan either beyesorno.
Thesaurus
Format:
<DS thesaurus="option"/>
Sample:
<DS thesaurus="yes"/>
- If this attribute exists, the document is marked as a thesaurus. Cannot be used with dict or srchlex.
- If a book is marked as a thesaurus, an attribute type with the code ‘T’ and name ‘Type’ is predefined. Currently defined values for this attribute type are ‘Syn’ and ‘Ant’ for synonym and antonym respectively. This attribute type can be used to define the type of sibling word.
-
optioncan either beyesorno.
Zoom
Format:
<DS zoom="percentage"/>
Sample:
<DS zoom="CODE"/>
- This is the general zoom percentage of the document.
-
percentagecan be any integer between50and300(default is100).
This is the paragraph style element. It must be an empty element. The first paragraph style listed will be considered the default paragraph style.
Sample <PS/>
Style Name
Format:
<PS st="string"/>
Sample:
<PS st="normal"/>
- The name of the paragraph style (required).
-
stringis the name of the style you wish to use. - Note that the first <PS/> tag will be considered the default style.
If a <p> tag does not have an
stattribute, it will use the first defined style.
Paragraph Wrapping Style
Format:
<PS wrap="wrappingStyle"/>
Sample:
<PS wrap="win"/>
- Changes the style of how paragraphs will wrap at the end of the document width.
wrappingStylecan be one of two wrapping styles:winwill wrap text to the next line at the end of the document width (default value).linewill NOT wrap text. A horizontal bar will appear to allow users to scroll through the text. (Used for books that need to maintain the original line structure).
Paragraph Direction
Format:
<PS dir="layoutDirection"/>
Sample:
<PS dir="ltr"/>
- Determines the paragraph direction.
layoutDirectioncan either beltr(left-to-right) orrtl(right-to-left).
Paragraph Justification
Format:
<PS just="justifySetting"/>
Sample:
<PS just="center"/>
- Determines the paragraph justification.
justifySettingcan beleft,center,right, orfull.
Text Style
Format:
<PS tSt="string"/>
Sample:
<PS tSt="normal"/>
- The name of a text style associated with this paragraph style. If no text style is active, this style will be used.
-
stringis the name of the text style you wish to use.
Space Before
Space After
Line Height
Line Spacing
Format:
<PS lnSp="value"/>
Sample:
<PS lnSp="p:12"/>
- Line spacing multiplier.
-
valuecan be any real number between0.25and32.0(default is1.0).
First Line Indent
Left Indent
Right Indent
Background Color of Text
Format:
<PS clrBk="color"/>
Sample:
<PS clrBk="128,128,128"/>
-
Set the background color for the paragraph. Defaults to white.
clrBkis a string of an RGB color for the font's color.
Define Tab Measurements
Format:
<PS tabs="value"/>
Sample:
<PS tabs="i:L2;R3"/>
-
Set the measurements of tabs for a paragraph. To add tabs in your
paragraph, refer to the
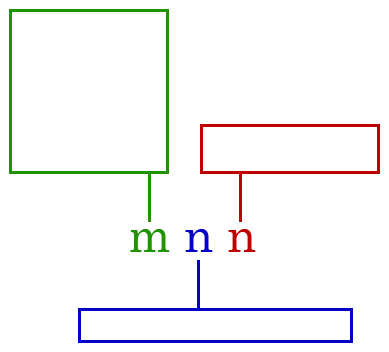
<tab/>section under Paragraph Format Elements. valuesfor one tab consists ofm:Tln[,n]where:- •
mcan be any of the following, and denotes the unit of measurement that should be used forn:t= twipsp= pointsi= inchesc= centimeters
- •
Tcan be:L= leftR= rightC= centerD= decimal
- •
lis optional to set the style of tab. If omitted, you'll get whitespace like any normal person would use.lcan be:d= dashp= dotu= underlinew= dot blankx= underline doty= dash blank
- •
nis the measurement size for the tab. For example, a 12-point left-justified tab would bep:L12.[,n]is an optional measurement size for iOS devices. The square brackets must be omitted, and are shown here only to demonstrate its optionality. For example, you can set a 12-point left-justified tab for the Windows program and a 6-point tab for the iOS app withp:L12,6.
- NOTE: to modify multiple tabs within a paragraph, you can add additional
;Tln[,n]codes after the initial set. For example, a 12-point left-justified tab followed by a 24-point center-justified tab could be set withp:L12;C24.
Default Tabs
Format:
<PS tabsDef="value"/>
Sample:
<PS tabsDef="i:L2;R3"/>
- Default tab sets for the paragraph. These sets occur after the last explicitly defined tab set.
-
valueis a single tab measurement value.
Left Border
Format:
<PS bdrL="value"/>
Sample:
<PS bdrL="t:20;36;double;red"/>
- The border to use for the left of the paragraph.
-
valuescan be one or multiple semicolon-separated values, of the format:m:n[,n];p[,p];l;clr, where:- •
mcan be any of the following, and denotes the unit of measurement that should be used fornandp:t= twipsp= pointsi= inchesc= centimeters
- •
nis the measurement size for the width of the border[,n]is an optional measurement size for iOS devices. The square brackets must be omitted, and are shown here only to demonstrate its optionality.
- •
pis the measurement size forpadding[,p]is an optional measurement size for iOS devices. The square brackets must be omitted, and are shown here only to demonstrate its optionality.
- •
lcan be:singledoubledotdashwave
- •
clris a color value for theborder color. - NOTE: all semicolon separated sections are optional, however the semicolons are not (e.g. if you wish to omit specifications for the 'l' and 'clr' options, your value might look something like this: "t:20;36;;").
- •
Right Border
Format:
<PS bdrR="value"/>
Sample:
<PS bdrR="t:20;36;double;red"/>
- The border to use for the right of the paragraph.
- For more information on the values this attribute takes, see the Left Border section.
Top Border
Format:
<PS bdrT="value"/>
Sample:
<PS bdrT="t:20;36;double;red"/>
- The border to use for the top of the paragraph.
- For more information on the values this attribute takes, see the Left Border section.
Bottom Border
Format:
<PS bdrB="value"/>
Sample:
<PS bdrB="t:20;36;double;red"/>
- The border to use for the bottom of the paragraph.
- For more information on the values this attribute takes, see the Left Border section.
This is the Text Style element. This element customizes the text at a character level. These are typically applied to paragraphs by adding the tSt attribute to the <PS/> tag. They can also define tagwords, which are used for applying metadata to a word or phrase.
Sample <TS/>
Style Name
Format:
<TS st="string"/>
Sample:
<TS st="normal"/>
- The name of the text style (required).
-
stringis the name of the style you wish to use.
Text Height
Text Width
Lexicon Name
Format:
<TS lexSt="string"/>
Sample:
<TS lexSt="Text"/>
- The name of the lexicon associated with this text style. Lexicons (or word lists) are often used to separate text from headings, footnotes, etc.
-
stringis the name of the lexicon you wish to use.
Font Face
Format:
<TS fFace="String"/>
Sample:
<TS fFace="Georgia"/>
- Regular font face.
-
stringis the name of the font face you wish to use.
Small Font Face
Format:
<TS fFaceSm="String"/>
Sample:
<TS fFaceSm="Georgia"/>
- Font face used for a small format ETBU.
-
stringis the name of the font face you wish to use.
Alternate Font Face
Format:
<TS fFaceAlt="String"/>
Sample:
<TS fFaceAlt="Georgia"/>
- Alternate font face to use if fFace does not exist.
-
stringis the name of the font face you wish to use.
Font Family
Format:
<TS fFamily="option"/>
Sample:
<TS fFamily="decorative"/>
- Font family (Not recommended).
-
optioncan bedecorative,default,modern,roman,script, orswiss.
Font Pitch
Format:
<TS fPitch="option"/>
Sample:
<TS fPitch="fixed"/>
- Font pitch (Not recommended).
-
optioncan bedefault,fixed,proportional, orvariable.
Font Quality
Format:
<TS fQuality="option"/>
Sample:
<TS fQuality="antialiased"/>
- Output quality of the font for the text.
-
optioncan beantialiased,cleartype,default,draft,non-antialiased, orproof.
Tag Type
Format:
<TS tagtype="code"/>
Sample:
<TS tagtype="t"/>
- Name of a tag type style to apply to this text style.
-
codeis a single character tag type code.
Text Color
Underline Color
Strikeout Color
Overbar Color
Underbar Color
Character Properties
Format:
<TS chrProp="option"/>
Sample:
<TS chrProp="bold"/>
- Character style of the text.
-
optioncan be one or many of each of the following options, but only one from each category:-
•
bold -
•
italic -
•
superscript|subscript -
•
hidden -
•
revised -
•
noindex -
•
underline|dash-underline|dot-underline|double-underline|wave-underline -
•
emboss|engrave|outline|shadow -
•
smcaps|allcaps|smcaps-up -
•
subword -
•
tag -
•
strikeout|dash-strikeout|dot-strikeout|double-strikeout|wave-strikeout -
•
overbar|dash-overbar|dot-overbar|double-overbar|wave-overbar -
•
underbar|dash-underbar|dot-underbar|double-underbar|wave-underbar
-
•
This is the lexicon element. This element is used to define separate categories that words in the document can be stored in. At least one <LEX> element must be defined. These are empty elements.
Style Name
Format:
<LEX st="string"/>
Sample:
<LEX st="myLexicon"/>
- The name of the lexicon (required).
-
stringis the name of the lexicon you wish to use.
Language
Format:
<LEX id="lang"/>
Sample:
<LEX id="en"/>
- The logical language of all the words in the lexicon.
-
langis the standard language name or standard language abbreviation for the lexicon.
Decimal Separator
Format:
<LEX dec="character"/>
Sample:
<LEX dec="."/>
- The character that should be used as the decimal separator for the lexicon. If specified, then grp must also be specified.
Group Separator
Format:
<LEX grp="character"/>
Sample:
<LEX grp=","/>
- The character that should be used as the numeric group separator for the lexicon. If specified, then dec must also be specified.
Ignore Characters
Format:
<LEX chrIgn="string"/>
Sample:
<LEX chrIgn="!@#$%^&*()_+-=[]{}|;':,./<>?"/>
- List of ignore characters. These are characters that will not be included in the text of a word.
-
stringis the characters you wish to ignore.
Break Characters
Format:
<LEX chrBrk="string"/>
Sample:
<LEX chrBrk=",—"/>
- List of break characters. These are characters that will automatically break a word.
-
stringis the characters you wish to use as break characters.
No-break Characters
Format:
<LEX chrNobrk="string"/>
Sample:
<LEX chrNobrk=",—"/>
- List of no-break characters. These are characters that will not automatically break a word.
-
stringis the characters you wish to use as no-break characters.
Text Style
Format:
<LEX tSt="string"/>
Sample:
<LEX tSt="normal"/>
- Default style for the lexicon.
-
stringis the name of the text style you wish to use.
Word Break Mode
Format:
<LEX wrdbrk="option"/>
Sample:
<LEX wrdbrk="style-brk"/>
- Word breaking mode for this lexicon.
-
optioncan behidden-nobrk,style-brk, orscript-nobrk.
This is the hyperlink style element. These define general styles used for hyperlinks. It must be an empty element.
Style Name
Format:
<HLS st="string"/>
Sample:
<HLS st="normal"/>
- The name of the text style (required).
-
stringis the name of the style you wish to use.
Hyperlink Type
Format:
<HLS type="option"/>
Sample:
<HLS type="icon"/>
- The hyperlink type.
-
optioncan either beiconorphrase.
Text Height
Text Width
Font Face
Format:
<HLS fFace="string"/>
Sample:
<HLS fFace="Georgia"/>
- Regular font face.
-
stringis the name of the font face you wish to use.
Small Font Face
Format:
<HLS fFaceSm="string"/>
Sample:
<HLS fFaceSm="Georgia"/>
- Font face used for a small format ETBU.
-
stringis the name of the font face you wish to use.
Print Font Face
Format:
<HLS fFacePrint="String"/>
Sample:
<HLS fFacePrint="Georgia"/>
- Font face used for printing.
-
stringis the name of the font face you wish to use.
Font Family
Format:
<HLS fFamily="option"/>
Sample:
<HLS fFamily="decorative"/>
- Font family (Not recommended).
-
optioncan bedecorative,default,modern,roman,script, orswiss.
Font Pitch
Format:
<HLS fPitch="option"/>
Sample:
<HLS fPitch="fixed"/>
- Font pitch (Not recommended).
-
optioncan bedefault,fixed,proportional, orvariable.
Font Quality
Format:
<HLS fQuality="option"/>
Sample:
<HLS fQuality="antialiased"/>
- Output quality of the font for the text.
-
optioncan beantialiased,cleartype,default,draft,non-antialiased, orproof.
Text Color
Underline Color
Strikeout Color
Overbar Color
Underbar Color
Character Properties
Format:
<HLS chrProp="option"/>
Sample:
<HLS chrProp="bold"/>
- Character style of the text.
-
optioncan be one or many of each of the following options, but only one from each category:-
•
bold -
•
italic -
•
superscript|subscript -
•
hidden -
•
revised -
•
noindex -
•
underline|dash-underline|dot-underline|double-underline|wave-underline -
•
emboss|engrave|outline|shadow -
•
smcaps|allcaps|smcaps-up -
•
subword -
•
tag -
•
strikeout|dash-strikeout|dot-strikeout|double-strikeout|wave-strikeout -
•
overbar|dash-overbar|dot-overbar|double-overbar|wave-overbar -
•
underbar|dash-underbar|dot-underbar|double-underbar|wave-underbar
-
•
Emphasis
Format:
<HLS em="option"/>
Sample:
<HLS em="yes"/>
- Forces emphasis of the target
-
optioncan either beyesorno.
Library
Format:
<HLS lib="option"/>
Sample:
<HLS lib="yes"/>
- Forces the execution of the hyperlink to look in the Library first for a matching target.
-
optioncan either beyesorno.
This is the level type element. It must be an empty element.
Level Type Code
Format:
<LVL code="code"/>
Sample:
<LVL code="c"/>
- The single character code to be used for the level type (required).
-
codeis a single character.
Level Name
Format:
<LVL name="string"/>
Sample:
<LVL name="Chapter"/>
- The name of the level type (required).
-
stringis the name of the level type you wish to use.
Plural Name
Format:
<LVL plural="string"/>
Sample:
<LVL plural="Chapters"/>
- The plural name of the level type (Recommended).
-
stringis the plural name of the level type you wish to use.
Separator
Format:
<LVL sep="string"/>
Sample:
<LVL sep=", "/>
- String to use in the citation line just before displaying this type of level.
-
stringis the character(s) you wish to use as a separator.
Text Style
Format:
<LVL tSt="string"/>
Sample:
<LVL tSt="normal"/>
- Text style to use Regular font face.
-
stringis the name of the text style you wish to use.
Hide
Format:
<LVL hide="option"/>
Sample:
<LVL hide="yes"/>
- This attribute is used to keep reference codes of this type from appearing in the display of the text. It will not hide the reference code from citations or output operations.
-
optioncan either beyesorno.
Hide Output
Format:
<LVL hideOutput="option"/>
Sample:
<LVL hideOutput="yes"/>
- This attribute is used to omit reference codes of this type from citations in copy/paste/print operations. It will not hide them in the text.
-
optioncan either beyesorno.
Internal
Format:
<LVL internal="option"/>
Sample:
<LVL internal="yes"/>
- This is the same as hidden, except that this code and all it’s children are also not shown in TOC or Citations.
-
optioncan either beyesorno.
Tag Type
Format:
<LVL tagtype="character"/>
Sample:
<LVL tagtype="T"/>
- Name of a tag type style to apply to this level type. The name and abbreviation of every level of this type will be indexed as the given tag type. If this is omitted, then the tag type defined in tSt will be used.
Lexicon Style
Format:
<LVL lexSt="string"/>
Sample:
<LVL lexSt="English"/>
- The name of the lexicon associated with this level type. Used only if the name will be indexed. If this is omitted, then the lexicon defined in tSt will be used if it is defined, otherwise the indexer will use the currently defined lexicon.
-
stringis the name of the lexicon style you wish to use.
This is the attribute element. These are used as attributes for reference levels. It must be an empty element.
Attribute Type Code
Format:
<ATTR code="code"/>
Sample:
<ATTR code="A"/>
- The single character code used for the attribute type (required).
-
codeis a single character.
Level Name
Format:
<ATTR name="string"/>
Sample:
<ATTR name="Level 1"/>
- The name of the level type (required).
-
stringis the name of the level you wish to use.
Plural Level Name
Format:
<ATTR plural="string"/>
Sample:
<ATTR plural="Level 1s"/>
- The plural name of the level type (Recommended).
-
stringis the plural name of the level you wish to use.
Tag Type
Format:
<ATTR tagtype="character"/>
Sample:
<ATTR tagtype="L"/>
- Name of a tag type style to apply to this attribute type. The name of every attribute of this type will be indexed as the given tag type.
-
characteris a single character.
Lexicon Style
Format:
<ATTR lexSt="string"/>
Sample:
<ATTR lexSt="English"/>
- The name of the lexicon associated with this attribute type. Used only if the name will be indexed. If this is omitted, then the lexicon defined in the tSt attribute of the Level Type for the given reference level will be used. If that is not defined, the indexer will use the currently defined lexicon.
-
stringis the name of the lexicon style you wish to use.
This is the tag type element. It must be an empty element. You can specify a maximum of 14 different tag types.
Level Type Code
Format:
<TAG code="code"/>
Sample:
<TAG code="T"/>
- The single character code to be used for the level type (required).
-
codeis a single character.
Level Name
Format:
<TAG name="string"/>
Sample:
<TAG name="Sample Tag"/>
- The name of the tag (required).
Plural Level Name
Format:
<TAG plural="string"/>
Sample:
<TAG plural="Sample Tags"/>
- The plural name of the level type (Recommended).
-
stringis the plural name of the level you wish to use.
Expand Tags
Format:
<TAG expand="option"/>
Sample:
<TAG expand="true"/>
- If yes, showing this tag type will automatically cause the expansion of any generic tag sections.
-
optioncan either beyesorno.
This is the reference tree element. Up to eight reference hierarchies can be defined in a document. This element allows the author to define a name for each of these “trees”. It must be an empty element.
Index
Format:
<TREE idx="number"/>
Sample:
<TREE idx="1"/>
- The index of the reference tree (required).
-
numberis an integer between1and8.
Reference Tree Name
Format:
<TREE name="string"/>
Sample:
<TREE name="Sample Tree"/>
- The name to associate with the reference tree (required).
-
stringis the name you wish to use for the tree.
Abbreviations
Format:
<TREE abrv="option"/>
Sample:
<TREE abrv="yes"/>
- If yes, then abbreviations will be shown in citations.
-
optioncan either beyesorno.
Show Citations
Format:
<TREE show="option"/>
Sample:
<TREE show="yes"/>
- If yes, then references from this tree will be shown in citations. If all trees are unspecified or set to no, then only the default tree will show.
-
optioncan either beyesorno.
Default Reference Tree
Format:
<TREE default="option"/>
Sample:
<TREE default="yes"/>
- Specifies the default reference tree. Only one tree can be marked as the default tree. If no trees are marked as the default, the first populated tree is used.
-
optioncan either beyesorno.
This is the phrase group element. This defines global properties for any phrase group that is used in the document. It must be an empty element.
Index
Format:
<GRP idx="index"/>
Sample:
<GRP idx="1"/>
- The index of the phrase group (required).
-
indexis an integer between0and32000.
Lexicon Style
Format:
<GRP lexSt="string"/>
Sample:
<GRP lexSt="English"/>
- The lexicon name to use for the phrase group (required).
-
stringis the name of the lexicon you wish to use.
The <DRM/> tag is called the copyright management tag because it allows publishers to set specific restrictions on a text. These restrictions prevent users from copying too much of a copyrighted book while still allowing them to copy modest snippets of text for research. Books must have at least 1,000 words in them to make the <DRM/> tag work.
Sample <DRM/>
<DRM restrictHiddenText="yes" KWICStyleReferenceList="yes" maxWordSpan="10" minWordGap="5" outputThreshold="500" maxOutputWords="3000" />
KWIC Style Reference List
Format:
<DRM KWICStyleReferenceList="boolean" />
Sample:
<DRM restrictHiddenText="yes" />
- Changes the Search Results view into KWIC (Keywords in context) list rather than the default context-based view.
-
The
maxWordSpanattribute is required when enabling the KWIC Style Reference List. - This feature is planned as a future development. It is not implemented yet.
-
booleancan beyesorno
Define Search Results Word Span
Format:
<DRM maxWordSpan="integer" />
Sample:
<DRM maxWordSpan="10" />
- Defines the maximum number of words before and after any hit word/phrase that can be output from the Search Results or similar reports.
-
If
KWICStyleReferenceListis enabled, this also defines the maximum number of words that can be shown before and after the hit word/phrase. - Defaults to 10.
-
If
integeris zero, then output and display revert to normal. - Max value is set to 1,000 but realistically should not exceed 100.
Require Word Gap between Search Results
Format:
<DRM minWordGap="integer" />
Sample:
<DRM minWordGap="20" />
- Prevents users from copying adjacent parts of the text, like when searching for all words in a text with *.
-
For situations where
maxWordSpanapplies, this is the maximum number of words that must occur between adjacent entries. If the gap is not satisified by the next hit, then context around adjacent entries will be hidden until the gap is satisfied. - The hit word/phrase will always be output.
-
integeris a value between 1 and 4,000. - If the value is zero, then overlap of adjacent entries is allowed (default behavior).
Define Total Words Allowed in Single Output
Format:
<DRM outputThreshold="integer" />
Sample:
<DRM outputThreshold="500" />
- Defines the maximum number of words that can be output from the Book View in any one copy/print/export.
- A warning will also be given each time cumulative output counts exceed this threshold.
-
If
integeris zero, no limit will be established on individual output operations and warnings will be based on percentage ofmaxOutputWords.
Limit Total Words Allowed in All Outputs
Format:
<DRM maxOutputWords="integer" />
Sample:
<DRM maxOutputWords="3000" />
- Sets a limit on the total number of words that any one user is allowed to copy. For a normal sized book, a typical value may be around 10% of the book.
- If the value is defined and is zero, all output is disabled. If this value is not defined, per user totals are not recorded. However, warnings may still be given if the copy threshold is violated.
This is the font embedding element. It must be an empty element. Use this element to embed a font that is used within the document in the ETBU file. The font will be extracted and installed when the document is opened in the viewer. This installation of the font is not permanent. It will be removed when the book is closed. Consequently, if a user copies text that uses a font not on their computer, programs like Word will look for an alternative font to use.
Font Family
Format:
<EMBED fFamily="string"/>
Sample:
<EMBED fFamily="Roboto"/>
- The family name of the font. For example: “Lato” or “Quivira” or “Roboto”. Do not specify a specific style such as bold or italics. The indexer will scan the system and embed all style variants of the requested font family (required).
-
stringis the name of the font family you wish to use.
These elements provide information needed to translate citations from a previous version of the file to the current version. For instance, if in a previous ETB version (ver. 5) a particular citation was: “/Introduction” and this was changed to “/Title/Introduction” in the new version (ver. 7), this element will provide enough information to make this translation. This information is used primarily during the upgrade of note files that were attached to previous versions of the document in order to translate old citations to the new ones so that the new position of the notes can be located. It is NOT used in the indexing of the document.
Each <UPGRADE> element includes one or more empty <REF/> elements. Each <REF/> element defines one citation translation. Multiple (up to 4) <UPGRADE> elements can be included, one for each previous version. However, at this point there is only one previous version that has been released.
Attributes <UPGRADE><UPGRADE/>
|
Name |
Values |
Description |
|---|---|---|
|
ver |
5, 7 |
The previous file format version. This is usually 5 (non-Unicode) or 7 (Unicode). |
|
file |
File title. String[63] |
This is the previous file title (i.e. the File name without the extension. (required). |
|
codepage |
Code page integer identifier. 1250 – Central European (Windows) 1251 – Cyrillic (Windows) 1252 – Western European (Windows) 1253 – Greek (Windows) 1254 – Turkish (Windows) 1255 – Hebrew (Windows) 1256 – Arabic (Windows) 1257 – Baltic (Windows) Others… |
This is the codepage that will be used to translate the old citation to Unicode. (required). (May only be needed for 5) |
|
edition |
Integer |
Edition of the file. Note: You also have to add the edition attribute to <etax>. |
Attributes <REF/>
|
Name |
Values |
Description |
|---|---|---|
|
old |
Citation (without offset) |
This is the citation in the previous version that is in need of translation. It can be a partial citation. (required). |
|
new |
Citation (without offset) |
This is the new citation. When a citation is in need of translation, if an old citation is found, then it will be replaced with the new citation. A citation is considered a match if the old citation completely matches the citation being translated (up to the number of levels defined). If the citation in question has levels beyond the match, they are concatenated onto the end of the translated citation. All entries will be checked and the longest match will be used for translation. (required). |
|
children |
yes | no |
If yes, then the citation will only be translated if the citation in question has child levels beyond the match. |
|
codepage |
Code page integer identifier. 1250 – Central European (Windows) 1251 – Cyrillic (Windows) 1252 – Western European (Windows) 1253 – Greek (Windows) 1254 – Turkish (Windows) 1255 – Hebrew (Windows) 1256 – Arabic (Windows) 1257 – Baltic (Windows) Others… |
This is the codepage that will be used to translate the old citation to Unicode. This will override the codepage specified in the <UPGRADE> element. |
Attributes <EMBED/>
|
Name |
Values |
Description |
|---|---|---|
|
fFamily |
Font Family Name Example: <EMBED fFamily=”Quivira”/> |
Embed a custom font that is installed on your computer. |
This is the index options element. It must be an empty element.
Attributes
|
Name |
Values |
Description |
|---|---|---|
|
wrdbrk |
Any combination of the following values: hidden-nobrk | style-brk | script-nobrk |
Word breaking options. This is the default for the whole document and can be overridden by the same attribute in the <LEX> element. |
|
stopwrds |
stop | go |
If a stopword file exists, this tells whether the words are stopwords or gowords. |
|
comp |
Any combination of the following values: off | on | text | index |
Compression options. Default is on. |
Paragraph Elements
The body of an ETAX document consists of a list of paragraph elements. There are currently two types of paragraphs: normal and table.
This is the normal paragraph element. This paragraph element can have any attributes that a <PS/> element can have except the name attribute. These attributes become overrides to the currently active paragraph style. The <p> element can also include the following attribute:
Paragraph Style
Format:
<p st="string"/>
Sample:
<p st="normal"/>
- The name of the paragraph style to use. If omitted the default paragraph style is assumed (i.e. the first paragraph style listed in the <sifx> element).
-
stringis the name of the style you wish to use.
This is the table paragraph element. It is considered an alternate type of paragraph and marks the start of a table. The <ptbl> element can have any of the attributes that the <p> element can have plus the following:
Column Width
Format:
<ptbl col="measurements"/>
Sample tables with three columns:
<ptbl col="*;*;*"/>
<ptbl col="50%;20%;30%"/>
<ptbl col="p:12,10;20%;*"/>
- The width of each column in the table. It is recommended the number of columns in a table be limited to no more than 100.
-
measurementsis a list of measurement values separated by semicolons. Each measurement value can be substituted with either an asterisk (*) or a percentage to represent an automatically calculated column width or a width based on a percentage of the line width. - NOTE: In a Word XML file, if any cell in a column has a different cell margin than the default for the table, an asterisk (*) well be used as the width for the column
Minimum Column Width
Table Type
Format:
<ptbl tblType="option"/>
Sample:
<ptbl tblType=flat/>
- Visual style of the table
-
optioncan either beflator3d.
Cell Vertical Alignment
Format:
<ptbl valign="option"/>
Sample:
<ptbl valign=top/>
- Vertical alignment of the text in each cell.
-
optioncan betop,center, orbottom.
Horizontal Padding
Vertical Padding
Spacing
Border
Inner Border
Border Color
The Table Row Element <trow></trow>
This is the table row element. It defines each row of a table. This element contains a list of <tcell> elements. Any text contained within a <trow> element is ignored unless it is within a child <p> element. This element can have any of the same attributes that a <tcell> element can have, except for spanCol and spanRow. These attributes will apply to each table cell on the row unless specifically overridden by the <tcell> element.
The Table Cell Element <tcell></tcell>
This is the table cell element. It defines each cell contained in a table row. This element contains a list of paragraph elements (either <p> or <ptbl> elements). Any text contained within a <tcell> element is ignored unless it is within a child <p> element. This element can contain the following attributes:
Cell Vertical Alignment
Format:
<ptbl valign="option"/>
Sample:
<ptbl valign=center/>
- Vertical alignment of the text in each cell
-
optioncan betop,center, orbottom.
Horizontal Padding
Vertical Padding
Column Span
Format:
<ptbl spanCol="number"/>
Sample:
<ptbl spanCol=2/>
- Number of columns for this cell to span. This number cannot exceed the number of columns left in the row. If a cell spans multiple columns, the spanned cells are NOT omitted.
-
numberis an integer between2and32.
Row Span
Format:
<ptbl spanRow="number"/>
Sample:
<ptbl spanRow=2/>
- Number of rows for this cell to span. If a cell spans multiple rows, the spanned cells on the following rows are NOT omitted.
-
numberis an integer between2and32.
Background Color
Left Border
Format:
<ptbl bdrL="value"/>
Sample:
<ptbl bdrL="t:20;36;double;red"/>
- The border to use for the left of the cell (see "Left Border" in <PS/>).
-
valueis the border you wish to use.
Right Border
Format:
<ptbl bdrR="value"/>
Sample:
<ptbl bdrR="t:20;36;double;red"/>
- The border to use for the right of the cell (see "Left Border" in <PS/>).
-
valueis the border you wish to use.
Top Border
Format:
<ptbl bdrT="value"/>
Sample:
<ptbl bdrT="t:20;36;double;red"/>
- The border to use for the top of the cell (see "Left Border" in <PS/>).
-
valueis the border you wish to use.
Bottom Border
Format:
<ptbl bdrB="value"/>
Sample:
<ptbl bdrB="t:20;36;double;red"/>
- The border to use for the bottom of the cell (see "Left Border" in <PS/>).
-
valueis the border you wish to use.
Inside a paragraph definition (<p>) all printable characters will be included in the text of a paragraph. Any character with a Unicode value less than a SPACE (i.e. tabs, line feeds, carriage returns, etc.) will be ignored. This allows for some formatting of the paragraph text in the XML document. Several empty elements are used instead of these characters:
How to Insert a Tab Character
Format:
<p>Leroy<tab/>Jenkins<tab/>24<tab/>$95,000</p>
Attributes
|
Element |
Description |
|---|---|
|
<br/> |
Inserts a hard return. This does NOT break the logical paragraph. |
|
<w/> |
Inserts a hard word break. |
|
<sp/> |
Inserts a hard non-breaking space. |
|
<xsp/> |
Inserts a hard breaking space. |
|
<zs/> |
Inserts a zero width space. |
|
<l/> |
Inserts a left indent. This is a tab that also sets the left indent property for the rest of the paragraph. NOT RECOMMENDED. Use the paragraph style indents instead. |
|
<r/> |
Inserts a right indent. The same as the left indent, except extends from the right side of the paragraph. NOT RECOMMENDED. Use the paragraph style indents instead. |
|
<d/> |
Inserts a double indent. This is equivalent to inserting both a left and a right indent simultaneously. NOT RECOMMENDED. Use the paragraph style indents instead. |
|
<lm/> |
Inserts a Unicode LTR (Left to Right) mark. U+200E |
|
<lo/> |
Inserts a Unicode LTR override mark. U+202D |
|
<le/> |
Inserts a Unicode LTR embedding mark. U+202A |
|
<rm/> |
Inserts a Unicode RTL (Right to Left) mark. U+200F |
|
<ro/> |
Inserts a Unicode RTL override mark. U+202E |
|
<re/> |
Inserts a Unicode RTL embedding mark. U+202B |
|
<pdf/> |
Inserts a Unicode PDF (Pop Directional Format) mark. This is used to terminate any of the above directional override or embedding modes (<lo/><le/><ro/><re/>). U+202C |
This element (<T>) is used to set the current text style. This is NOT an empty element. The text style will remain in effect for all text that is contained within the element and will override any text style specified in the paragraph element or the currently active paragraph style. If no text style element is output, or if text occurs outside this element, the text style specified in the paragraph or paragraph style will be used.
Text Style
Format:
<T st="string">...</T>
Sample:
<T st="normal">Sample text</T>
- The name of a <TS> record in the sifx (required).
-
stringis the name of the text style you wish to use.
Every attribute of a text style can be overridden individually by several Text Style Override Elements. These elements are NOT empty elements. Their attributes remain in effect for all text that is contained within the element. These elements are listed below:
Attributes
|
Element |
Description |
|---|---|
|
<b> |
Turns bolding on/off. |
|
<i> |
Turns italics on/off |
|
<s> |
Turns superscript or subscript on/off |
|
<u> |
Turns underline on/off. |
|
<o> |
Turns strikeout on/off. |
|
<ob> |
Turns overbar on/off. |
|
<ub> |
Turns underbar on/off. |
|
<c> |
Turns all caps or small caps on/off. |
|
<e> |
Turns on a special effect like embossing, engraving, outline, or shadow. |
|
<x> |
Turns indexing on/off. |
|
<rev> |
Turns on/off revised text. |
|
<h> |
Turns on/off hidden text. |
|
<f> |
Changes the font. |
|
<lex> |
Changes the currently active lexicon. |
|
<sz> |
Changes the size of the text. |
|
<tt> |
Changes the current tag type. |
|
<t> |
Turns the general tagtype flag on/off. |
|
<sw> |
Turns the subword flag on/off. All text in this element will be indexed as a subword. |
|
<cf> |
Changes the foreground color. |
|
<cb> |
Changes the background color. |
|
<cu> |
Changes the underline color. |
|
<co> |
Changes the strikeout color. |
|
<cob> |
Changes the overbar color. |
|
<cub> |
Changes the underbar color. |
|
<ch> |
Forces hard characters. Characters with this style cannot be delimiters. See “Hard Characters Element” below. |
Many of the above elements use similar attributes. We will explain each below in groups.
Attributes <b><i><x><rev><h><t><sw>
|
Name |
Values |
Description |
|---|---|---|
|
val |
on | off |
This overrides the corresponding text style property and turns the property either on or off. By default, (or if this attributes is omitted) the property is turned on. |
Attributes <s>
|
Name |
Values |
Description |
|---|---|---|
|
val |
super | sub | off |
This overrides the script text style property and either turns off any scripting, or turns on superscript or subscript. By default, (or if this attributes is omitted) superscript is turned on. |
Attributes <u><o><ob><ub>
|
Name |
Values |
Description |
|---|---|---|
|
val |
single | dash | dot | double | wave | off |
This overrides the corresponding text style property and sets the line style accordingly. By default, (or if this attributes is omitted) the single line style is used. |
Attributes <c>
|
Name |
Values |
Description |
|---|---|---|
|
val |
small | all | up | off |
This overrides the caps text style property and sets the style accordingly. By default, (or if this attributes is omitted) small caps is used. The up style will show the text as small caps, but index the text as all caps.
all makes the word in caps for the text and WordWheel. |
Attributes <e>
|
Name |
Values |
Description |
|---|---|---|
|
val |
outline | emboss | engrave | shadow | off |
This overrides the effect text style property and sets the style accordingly. (required) |
Attributes <f>
|
Name |
Values |
Description |
|---|---|---|
|
fFace |
String |
Regular font face |
|
fFaceSm |
String |
Font face used for a small format ETBU. |
|
fFacePrint |
String |
Font face used for printing. |
|
fFamily |
decorative | default | modern | roman | script | swiss |
Font family. (Not recommended). |
|
fPitch |
default | fixed | proportional | variable |
Font pitch. (Not recommended). |
|
fQuality |
antialiased | cleartype | default | draft | non-antialised | proof |
Output quality of the font for the text. |
Attributes <lex>
|
Name |
Values |
Description |
|---|---|---|
|
st |
The name of a <LEX> record in the sifx. |
This changes the currently active lexicon. Any words in this element will be indexed into that lexicon. |
Attributes <sz>
|
Name |
Values |
Description |
|---|---|---|
|
val |
Either a measurement value, or a percentage, or one of the following: s | v | t | L | V | H These represent small, very small, tiny, large, very large, and huge sizes relative to the current base font size. |
This is a typical measurement value or a percentage. If this is a percentage then the size of the text is calculated dynamically by a percentage of the current window size. This is useful for writing title pages. |
Attributes <tt>
|
Name |
Values |
Description |
|---|---|---|
|
st |
The code defined in a <TAG> record in the sifx. Single Character |
This changes the currently active tag type. |
Attributes <cf><cb><co><cu><cob><cub>
|
Name |
Values |
Description |
|---|---|---|
|
val |
A color value |
This overrides the corresponding color property. |
Reference level elements <R/> are used to define a hierarchical structure to the file. This structure is used as an address in hyperlinks to properly position when a hyperlink is taken. Up to eight different hierarchy “trees” can be defined in a single document. These “trees” can be overlapping. For instance, you may want a section/sub-section hierarchy, or a book/chapter/verse hierarchy, or a page/paragraph hierarchy all in the same document. There is no way in XML to define these multiple overlapping hierarchies. Therefore, we have implemented these elements as empty elements. When a reader encounters one of these elements they must record the level and tree and keep this reference active until the next element for the same tree is found.
If you want to index the values of a level, please see the <LVL> element in the <sifx> section.
Attributes <R/>
|
Name |
Values |
Description |
|---|---|---|
|
ref |
A reference definition in the following format: l,d[,t]:name
Where: l= Code for a <LVL> record. Where: d= Number of the tree depth. Where: t= The tree number (1-8). Where: name= The name of the level. |
This is the definition of this reference code. For instance, if we are defining a reference level for the title page of a document in the first reference tree we could define it as such: ref=”S,1:Title Page” The first paragraph in the title page could be: ref=”P,2:1” This assumes that <LVL> records were defined in the sifx that have the codes ‘S’ and ‘P’. Note that the level number for the title page is 1, while the level number of the paragraph is 2. This means that the paragraph is below (or part of) the title page in the hierarchy. Notice also that the tree number has been omitted. The default tree is always the first tree. Any text after the colon is the name of the level. This name may be omitted, however, if it is, then no text will be displayed in the table of contents for this reference level (required). |
|
abrv |
String |
An abbreviation for the name of the level. |
|
hide |
yes | no |
This attribute is used to keep reference codes of this type from appearing in the display of the text. It will not hide the reference code from citations or output operations. |
|
hideOutput |
yes | no |
This attribute is used to omit reference codes of this type from citations in copy/paste/print operations. It will not hide them in the text. |
|
internal |
yes | no |
This is the same as hide, except that this code and all it’s children are also not shown in TOC or Citations. |
|
attr |
A reference attribute definition in the following format: a:name[;a:name]* Where: a= Code for a <ATTR> record. Where: name= The name of the attribute. |
Each reference level can be given attributes defined by the author. These attributes consist of a type (defined in the sifx) and a name. For instance, you may want to give a “Topic” to a section: attr=”T:Budget” You may give more than one attribute: attr=”T:Budget;S:President” This assumes that <ATTR> records were defined in the sifx that have the codes ‘T’ and ‘S’ for possibly “Topic” and “Speaker” respectively. These categories are completely author defined and can be used to help limit or bound searches. |
The <Re/> element is used to terminate the last level for a given tree. By default, once another reference element is encountered for a given level and tree, and other elements currently active for that tree which have a level greater than or equal to than the new element are automatically terminated. You may use this element to terminate a level manually.
Attributes <Re/>
|
Name |
Values |
Description |
|---|---|---|
|
tree |
A tree number (1-8) |
This is the tree that should terminate the last reference level. Be default (if this attribute is omitted) the first tree is used. |
There are several different types of hyperlinks:
- Cross reference hyperlinks. These are used to jump from one section of text to another. The destination may also be in a completely different document.
- Image hyperlinks. These are used to display a picture or image in a separate window.
- Shell hyperlinks. These are used to spawn a separate application, start an email, or open a web browser.
- DDE hyperlinks. These are used to control a second application.
The type of hyperlink can be determined from a code in the st attribute. Other attributes are used to define other properties of the hyperlink. Depending on the style of the hyperlink (either phrase or icon as defined in the <HLS> record in the sifx) the hyperlink is either an empty element (icon) or not (phrase). If the hyperlink is not an empty element, clicking on any text in the hyperlink element will execute the hyperlink.
Attributes <H/>
|
Name |
Values |
Description |
|---|---|---|
|
st |
The style of the hyperlink in the following format: t:name
Where: t= X | I | S | D Where: name= The name of an <HLS> record. |
The type codes are defined as follows: X= A cross-reference hyperlink I= An image hyperlink S= A shell hyperlink (calls the ShellExecute function in Windows) D= A DDE hyperlink (required). |
|
file |
A path to a file, usually relative to the location of the current document. The following macros may be used to specify additional paths: %TEXT% - The current document path. %PROGRAM% - The WordCruncher program path. |
This is used to specify an external file in:
It is not used for DDE hyperlinks – (st=”X|I|S”). |
|
fileAux |
One or more paths to files using the same rules as the file attribute. Files are specified using the following format: file[;file]* |
Auxiliary files used to further define which book from a library should be used as the target. If the desired target is a Book Set, then this attribute can contain the other files in the set. The software will attempt to match each auxiliary file to other files in the book set.
This is only used in cross-reference hyperlinks (Optional) - (st=”X”). |
|
cit |
A forward slash (/) delimited string of reference names optionally prefaced by a tree number and optionally terminated by a word offset or a reference gap number: [t:]/name[/name]*[ (:word[,subword [,tagword]]) | (#gap)] |
This is the destination reference hierarchy path to position to. Examples might be: cit=”/Section 1/Sub-Section 5” cit=”2:/Page 1/Paragraph 3” cit=”/Section 1/Sub-Section 5:3”
This is only used for cross-reference hyperlinks - (st=”X”). |
|
citRng |
One or more citation ranges delimited by semicolons: cit[-cit][;cit[-cit]]* Where cit is the same as in the cit attribute, without the optional tree number. Also, the cit can be a relative citation based on the citation in the cit attribute. |
This is used to emphasize a range of words or references when a hyperlink is taken. Each citation can be a full citation as defined in the cit attribute (without the optional tree number). Or it can be a relative citation based on the citation given in the cit attribute. If it is a relative citation, the cit should NOT be prefaced by a forward slash, and can optionally have one or more “..” levels which will remove one child level from the base citation. For instance:
cit=”/Section/1” citRng=”1-2” will emphasize /Section/1 through /Section/2
cit=”/Section/3/7” citRng=”6-../4/9” will emphasize /Section/3/6 through /Section/4/9.
This is only used for cross-reference hyperlinks - (st=”X”). |
|
idx |
Number |
Some image formats can contain multiple images. This is the index of the image in the file. The default is the first image.
This is only used with image hyperlinks - (st=”I”). |
|
page |
Number |
Some images formats can contain multi-page images. This is used to specify a particular page.
This is only used with image hyperlinks - (st=”I”). |
|
rect |
This is a rectangle measurement value: m:(x,y,w,h) Where m=t|p|i|c t->twips p->points i->inches c->centimeters Where x,y,w,h= Real numbers. These correspond to the left, top, width, height dimensions of the source image. |
This is used to crop the output of an image.
It is only used with image hyperlinks - (st=”I”). |
|
op |
String |
This is an OLE verb such as “open” or “print”.
It is only used with shell hyperlinks- (st="S"). |
|
cmd |
String |
This is a user defined command string.
It is used with shell hyperlinks and DDE hyperlinks - (st=”S|D”).
If path represents a data file, this should be omitted. The system will find the appropriate executable to show the file if it has been properly registered. |
|
path |
A path. The same macros that were used for the file attribute can be used here. |
This is a path to use.
It is only used with shell hyperlinks - (st=”S”). |
Inline images are usually empty elements. If no file attribute is given for an inline image, then the text inside the element must consist of a base64 encoded image. No other text is allowed inside an inline image hyperlink.
Attributes
|
Name |
Values |
Description |
|---|---|---|
|
file |
A path to a file, usually relative to the location of the current document. The following macros may be used to specify additional paths: %TEXT% - The current document path. %PROGRAM% - The WordCruncher program path. |
This is used to specify an external image file in an inline image (Optional). If this is omitted for an inline image then the text of the element must be a base64 encoded image. |
|
idx |
Number |
Some image formats can contain multiple images. This is the index of the image in the file. The default is the first image. |
|
page |
Number |
Some images formats can contain multi-page images. This is used to specify a particular page. |
|
dim |
The display dimensions of the image in a paired measurement value format: m:(x,y)[,(x,y)] Where m=t|p|i|c t->twips p->points i->inches c->centimeters Where x,y= Real numbers. The second optional numbers are for small format ETBU. |
This is the logical output dimensions of the image. (required)
If one of the values is zero, the value will be automatically calculated from the image aspec ratio. If both values are zero, the image size will be calculated from the stored resolution of the image. |
|
desc |
String |
Image description used in the ETGU. Omit if no image data! |
|
rect |
This is a rectangle measurement value: m:(x,y,w,h) Where m=t|p|i|c t->twips p->points i->inches c->centimeters Where x,y,w,h= Real numbers. These correspond to the left, top, width, height dimensions of the source image. |
This is used to crop the output of an image. |
These elements are used to place small comments or notes above or below the main text in the document. It is commonly used to place furigana text in Japanese documents. The ruby text is positioned relative to any text that is between the begin element (<rt/>) and the end element (<rte/>). Both of these must be empty elements.
Attributes
This element can be used to change the default behavior of the word parse in the WordCruncher Indexer program. The word parser does a very good job at finding the appropriate boundary between words. However, there may be times that the Indexer selects a word boundary that is not optimal for a particular situation. Any text inside a <ch> element (including whitespace) will be part of the current word and will not delimit the word. Please note that a word may still be terminated by the end of a paragraph, change in lexicon, or any other markup (<tab/> for instance) that would otherwise place a physical break in the word. Likewise, the word may not be automatically terminated at the end of the element if it is not immediately followed by a delimiter.
This element is used to create phrasal groups of words which are displayed on the word wheel. Since formatting elements can be used within these groups, and the groups cannot be split up, these are implemented as empty elements. When the reader encounters a group beginning element <g/> this group must remain active until the corresponding group ending element <ge/> is found. The exclusion elements (<gx/> and <gxe/>) work similarly, except these are used to exclude words from the middle of a phrase.
Attributes
|
Name |
Values |
Description |
|---|---|---|
|
idx |
Number between 1 and 32767 |
This is the index of the group. This is used to match up <g/>-<ge/> and <gx/>-<gxe/> elements. If this is omitted, the index defaults to zero. This is useful if nested groupings are desired. |
|
lex |
String |
A lexicon name in which to place the indexed phrase. This attribute is not used for the <ge/>, <gx/> and <gxe/> elements. If this is omitted, the lexicon will default to either the lexicon specified in the <GRP> element in the sifx, or to the active lexicon when the element was first encountered. |
|
pos |
The part of speech used for the whole phrase group, if applicable. |
This element is used to include another file. If the included file has its own <sifx> element, it will be ignored. Consequently, indexer warnings/errors arise when the included file has SIFX elements that the main ETAX file does not have defined in its SIFX element. This element cannot be a child element of a <p> or <ptbl> element.
Sample Include Tag
Format:
<include file="pathName"/>
Sample:
<include file="include/file1.etax"/>
- Embeds an exteral file into the ETAX. You can embed ETAX, RTF, TXT, or XML 2003 files.
pathNameis a string of the included file's file path in relationship to the main ETAX file.
Part of Speech Tagging
WordCruncher has the ability to attach a part of speech code to each word and include it with the word information in the index (WordWheel). These part of speech codes are built with predefined tags (see below for a chart of tags) which can be organized in a hierarchical manner. For instance, the part of speech code for a singular, common noun can be written with the three tags: “n.comm.sing”. While WordCruncher provides a rich set of predefined part of speech tags, there are occasions where they may be insufficient to fully describe a part of speech code. In these cases, some user defined tags can be added.
The Indexer does not currently tag texts for part of speech. It is recommended that you use an external part of speech tagger like Stanford NLP or TreeTagger to tag your texts. Other resources like NLTK, Stanza, or Spacy with Python are also useful for tagging texts. These part of speech taggers produce abbreviated markup codes like NN1 for singular nouns and NN2 for plural nouns. WordCruncher can also accept these markup codes for parts of speech, but an XML file called the EPOSX is needed to define how these markups are translated to WordCruncher part of speech codes.
Below are a few example EPOSX files for download. They can be used or modified to fit your needs.

It is encouraged that you use one of the EPOSX files from our GitHub to create your custom EPOSX. However, here is the basic template needed for the file.
<eposx name="C5" wordSeparator="_" ambiguitySeparator="-">
<userTags>
<tag code="wh" name="Wh- Words" />
</userTags>
<markups>
<markup text="AJC" code="adj.comp" />
</markups>
</eposx>
| Attribute | Example Values | Description |
|---|---|---|
| title | C5 C8 Stanza-English |
Give a name to the type of part of speech, preferably in reference to the name of the tagger used. |
| wordSeparator | _ (Default) / |
The character that is used to mark a word with the part of speech. If an underscore is the word separator, then your text should look like “word_NN0”. |
| ambiguitySeparator | - (Default) ? |
This character is used within part of speech codes. Taggers may provide two parts of speech if there is ambiguity. If a hyphen is used for the ambiguity separator, then your text should look like “swimming_NN0-VBG”. |
WordCruncher books are prepared with an underscore as the word separator and a hyphen as the ambiguity separator, as shown below:
<eposx title="C5" wordSeparator="_" ambiguitySeparator="-">
<eposx title="C8" wordSeparator="_" ambiguitySeparator="-">
WordCruncher has predefined tags that must be the first tag listed in each part of speech code. We call these “Primary” tags. Primary tags can also be used as “Secondary” tags if needed. For example, “n.adv” can be used to mark an adverbial noun. Below are listed the Primary tags. Use the “Tag Code” when defining a part of speech code. The “Tag Name” is given merely for convenience and readability.
| Name | Code | Abbreviation |
|---|---|---|
| adjective | adj | j |
| adverb | adv | r |
| alphabet | alph | z |
| article | art | a |
| circumposition | circ | cp |
| classifier | clf | cl |
| clitic | clitic | ct |
| conjunction | conj | c |
| determiner | det | d |
| existential | exist | ex |
| interjection | interj | ! |
| noun | n | n |
| null | null | nl |
| numeral | num | # |
| other | oth | o |
| postposition | postp | pp |
| preposition | prep | p |
| pronoun | pron | pn |
| particle | ptcl | pt |
| punctuation | punct | * |
| suffix | sufix | + |
| unclassified | uncl | u |
| verb | v | v |
Secondary tags are categorized in this table by the grammatical category that are usually associated with them. However, they can be used as any category based on your part of speech schema. It is recommended that only one tag per category be used when defining a part of speech code. User tags can be added to this list of secondary tags if further defintion is required.
| Name | Code | Abbreviation |
|---|---|---|
| Verb | ||
| lexical | lex | lex |
| auxiliary | aux | aux |
| modal | mod | mod |
| semiauxiliary | semiaux | semiaux |
| Noun | ||
| common | comm | c |
| proper | prop | pr |
| Common Noun | ||
| unit | unit | unit |
| direction | dir | dir |
| temporal | temp | temp |
| Noun Action | ||
| subject | sbj | sbj |
| object | obj | obj |
| Adjective and Adverb | ||
| comparative | comp | comp |
| superlative | superl | sup |
| evaluative | eval | eval |
| positive | pos | pos |
| negative | neg | neg |
| attributive | attr | attr |
| predicative | pred | pred |
| degree | deg | deg |
| Numeral | ||
| cardinal | card | card |
| ordinal | ord | ord |
| fraction | frac | frac |
| Conjunction | ||
| coordinating | coord | coord |
| subordinating | subord | sub |
| correlative | corr | corr |
| Pronoun and Determiner | ||
| definite | def | def |
| indefinite | indef | indef |
| demonstrative | dem | dem |
| exclamative | excl | excl |
| interrogative | interrog | interrog |
| personal | pers | pers |
| reflexive | refl | refl |
| irreflexive | irrefl | irrefl |
| relative | rel | rel |
| substitutive | substit | subst |
| independent | indep | ind |
| Tense | ||
| conditional | cond | cond |
| future | fut | fut |
| past | past | past |
| present | pres | pres |
| Aspect | ||
| imperfect | imperf | impf |
| perfect | perf | pf |
| progressive | prog | prog |
| aorist | aor | aor |
| pluperfect | pluperf | plpf |
| State | ||
| absolute | absol | absol |
| construct | constr | constr |
| Voice | ||
| active | act | act |
| passive | pass | pass |
| middle | mid | mid |
| causative | caus | caus |
| Mood | ||
| indicative | indic | indic |
| imperative | imp | impv |
| subjunctive | subj | subj |
| optative | opt | opt |
| infinitive | inf | inf |
| finite | fin | fin |
| gerund | ger | ger |
| participle | ptcp | pple |
| jussive | juss | juss |
| cohortative | hort | cohrt |
| Person | ||
| firstperson | 1 | 1 |
| secondperson | 2 | 2 |
| thirdpersion | 3 | 3 |
| Case | ||
| nominative | nom | n |
| genitive | gen | g |
| possessive | poss | poss |
| dative | dat | d |
| accusative | acc | a |
| locative | loc | loc |
| vocative | voc | voc |
| instrumental | instr | instr |
| absolutive | abs | abs |
| ergative | erg | erg |
| Gender | ||
| masculine | masc | m |
| feminine | fem | f |
| neuter | neut | nt |
| universal | univ | univ |
| Animacy | ||
| animate | anim | anim |
| inanimate | inanim | inan |
| human | hum | hum |
| nonhuman | nonhum | nonhum |
| Number | ||
| singular | sing | s |
| plural | pl | p |
| dual | dual | du |
| Honorifics | ||
| formal | forml | forml |
| informal | inform | inform |
| polite | pol | pol |
| royal | roy | roy |
| Other | ||
| abbreviation | abbr | abbr |
| contraction | contr | contr |
| foreign | foreign | forn |
| headline | head | head |
| title | title | title |
| marker | mark | mark |
| pronominal | pronom | pronom |
| truncated | trunc | trunc |
In the <userTags> section of an EPOSX, a user can add up to 64 tag elements that are not specified in secondary tags list. Codes must have no spaces, word separator character, or ambiguity separator character.
Individual tags need to be in an empty <tag/> element. There are two attributes for this tag: code and name.
TABLE
Below are some examples of tags that you can make.
<userTags>
<tag code="wh" name="Wh-words" />
<tag code="that" name="That" />
<tag code="of" name="Of" />
<tag code="be" name="Be verbs" />
<tag code="do" name="Do verbs" />
<tag code="have" name="Have verbs" />
</userTags>
Part of Speech Markups
The <markups> element is the XML element where all markups defined by external taggers are given WordCruncher part of speech code equivalents using the <markup/> element. This element has two required attributes: text and code.
TABLE
Example Text
With the EPOSX prepared correctly, the text in the ETAX needs to follow the character separators. An example paragraph should look like this:
<p>The_AT quick_JJ brown_JJ fox_NN1 jumped_VVD over_II the_AT lazy_JJ dog_NN1.</p>
Alternatively, a user can use the default WordCruncher markup for tagging text. If done this way, you won't need to add anything else to the <EPOSX>.
<p>The_art quick_adj brown_adj fox_n.sing jumped_v.past over_prep the_art lazy_adj dog_n.sing.</p>
Available Features: Search features and the Neighborhood Report are available for part of speech books. Other reports, such as the Phrase Compare Report, will be updated later to use POS functionality.
Punctuation: Normal punctuation that is not defined in as a word
separator or
ambiguity separator will not be used for parts of speech. That means that it’s okay to
have
punctuation right after a part of speech tag without adding a zero space <zs/> tag
before
punctuation.
For example, if a sentence ends with “dog_NN1.”, then the period at
the end
will not be indexed as part of the POS tag.
If the word separator or ambiguity separator are part of words, then a <ch> tag should be wrapped around these characters. For example, my_function_NN0 will cause a problem because the underscore initiates the part of speech. Since function_NN0 is probably not the desired POS, this should be modified to my<ch>_</ch>function_NN0.
Attributes, Tag Words, Reference Levels: Any text that is in an attribute, tag word, or reference level will not be indexed for POS tags.
The Translation Table Element <ettx></ettx>
The ETTX tag is used for synchronizing two versions or translations of the same book. Books that use the ETTX tag in the WordCruncher Bookstore include The Scriptures, Quran, and TED Talks. An ETTX tag is also necessary when making footnotes for a book unless they are combined in a BookSet.
You should be intimately familiar with the interaction between the <LVL/> tags, <R/> tags, and <TREE/> tags before trying to synchronize books.
When using an ETTX tag between books, you must remember to:
- Use the same LVL tags between both books within the SIFX. If both
books have chapters, then it would make sense to have
<LVL code="c" name="Chapter" plural="Chapters"/>in each SIFX. - Keep the table of contents similar for each book. The more similar your table of contents, the simpler the ETTX tag will be. If the tables of contents are the exact same for each book, then your ETTX will look like this:

Basic ETTX Example
Format/Sample:
<ettx>
<table id="{f0a35742-45c3-4f96-966b-8f42f87011ef}" name="Tree Name" tree="1"/>
</ettx>
-
The
idis a UUID. Generate a UUID: - The
nameis the same as the name value from your TREE tag. - The
treeis the index number of the TREE for which you’re synchronizing. Refer to the number in your TREE tag. This usually will be 1, unless you are using a secondary TREE solely for the purpose of synchronization.
If your table of contents are not the same, you will need to map the differences between the two of them. This is done by adding MAP tags between each tag that is different.
<R/> tag.<R/> tag.1. Identify the 1-letter code
The<R/> tags for each book looks like this:
<R ref="V,1:Holy Bible"/>
<R ref="V,1:Santa Biblia"/>
Both of these <R/> tags start with V. This is the 1-letter code we’ll need.
2. Create a LEVEL tag
The LEVEL tag has one mandatory attribute: type. Add the 1-letter code as the value of attribute.
3. Create a MAP tag within the LEVEL tag
To make a map between the Holy Bible and Santa Biblia, the MAP tag will look like this:
<map sync="Holy Bible" src="Santa Biblia"/>
It should be a child of the LEVEL tag, so place it within the <level type="v"> tag:
<level type="V">
<map sync="Holy Bible" src="Santa Biblia"/>
</level>
4. Add a MAP tag for each reference level
Repeat step 3 for each reference level in the table of contents, assuming each one has differing text.
<level type="V">
<map sync="Holy Bible" src="Santa Biblia"/>
<map sync="Old Testament" src="Antiguo Testamento"/>
<map sync="New Testament" src="Nuevo Testamento"/>
…
</level>
Note that a separate LEVEL tag should be made for each 1-letter code that needs to be mapped. For example, the books of The Scriptures, (e.g. Genesis, Exodus), have the code B (for Book). That LEVEL tag looks like this:
<level type="B">
<map sync="Genesis" src=" Génesis"/>
<map sync="Exodus" src=" Éxodo"/>
</level>
If the translation table is updated after publishing the book to the Bookstore, specific attributes must be changed on the ETTX tag before a new version of the book is added in the Bookstore.
This section needs to be finished!
The Morphology Table Element <emtx></emtx>
This element is identical to the contents of the Morphology Table File described in the Example Files section. If the emtx attribute of the <etax> element is omitted, this element is used.
Morphology Table File (EMTX)
This file defines the optional morphology tables used to search for word attributes (or word tags). All values of name and code attributes are free form based upon the content of the target book. <title> elements are merely organizational. Below is an abbreviated example file:
<?xml version="1.0" encoding="utf-16" standalone="yes"?>
<emtx>
<tree name="Hebrew Scripture Word Tags" lex="English (Word Tags)" id="XXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
<title name="Language">
<item name="Hebrew (Heb)" code="Heb" />
<item name="Aramaic (Aram)" code="Aram" />
</title>
<title name="Grammatical Tags">
<item name="PARTICLE" code="PARTICLE">
<item name="article (art)" code="art" />
<item name="conjunction (conj)" code="conj" />
<item name="adverb (adv)" code="adv" />
...
</item>
<item name="PRONOUN" code="PRONOUN">
<item name="interrogative (interr)" code="interr" />
<item name="independent (indep)" code="indep">
<title name="Person">
<item name="1st Person (1)" code="1" />
<item name="2nd Person (2)" code="2" />
<item name="3rd Person (3)" code="3" />
</title>
...
</item>
</item>
<item name="NOUN" code="NOUN">
<item name="proper" code="proper" />
<item name="common (comm)" code="comm">
<title name="Gender">
<item name="masculine (masc)" code="masc" />
<item name="feminine (fem)" code="fem" />
<item name="both" code="both" />
</title>
...
</item>
</item>
...
</title>
<title name="Other Tags">
<item name="Word Separator" code="/" />
<item name="Paragraph" code="¶" />
<item name="Qere without Ketiv" code="Qere-without-Ketiv" />
</title>
</tree>
</emtx>