WordCruncher Monthly
Language Learning Tip #1:
How WordCruncher Can Identify Authentic
Texts from a Vocabulary List
By Jesse Vincent
Introduction
Many curricula for language classes today use word frequency to identify sets of important vocabulary, but they tend to lack texts that use the language authentically. If you’ve ever been in a foreign language class, you might have been assigned a text that used all the vocabulary words you were studying. The text might have seemed a little forced or awkward, probably because it was written in order to include the full vocabulary list. But what if we could identify texts that used the vocabulary authentically rather than artificially? As a speaker and student of eight languages, I’ve used WordCruncher to identify samples of authentic language based on a vocabulary list, and I’ve found it to be a fun way to practice vocabulary through reading and listening. Not only can we use WordCruncher to search for how many times words occur, but we can also find texts that have the most occurrences and whether or not they contain all the vocabulary words from our search. Let's explore a method that allows us to identify articles from the TED Talk Corpus that are highly concentrated with key vocabulary.
Step # 1: Starting with a vocabulary list
Obviously, the first step is to have a vocabulary list ready. As a sample, I’ll be using BYU’s English Language Center’s vocabulary list called LEAP. Each week, language learners study 10-12 vocabulary words a week. The first list for a beginner includes:
- area (noun)
- business (noun)
- company (noun)
- create (verb)
- different (adjective)
- follow (verb)
- happen (verb)
- hold (verb)
- idea (noun)
- include (verb)
Step #2: Choosing a Corpus Designed for Language Learners
A corpus is a collection of texts designed for a type of analysis. COCA (Corpus of Contemporary American English), for example, is a collection of texts from contemporary American English. It’s a web tool that provides information about a word or phrase’s frequency, collocations, definition, and more.
In WordCruncher, we have a few corpora like EEBO (Early English Books Online) and EVANS (Early American Imprint Collection). However, these weren’t designed for language learners, as these corpora contain older English. The TED Talk Corpus, however, was designed for language learners and teachers. It allows them the ability to read the English transcripts alongside another language or open up ted.com to watch the video of the talks.
The TED Talk corpus can also search for words by headword (a.k.a. lemma), meaning that a search for “idea” will search for both the words “idea” and “ideas,” which allow learners to find various forms of the same word.
You can download the TED Talk Corpus in English and Spanish for free!
Download TED Talk CorpusStep #3: Searching for the Academic Vocabulary
There are two ways that we can search for all the vocabulary at once: ‘or’ logic and phrase lists. Admittedly, phrase lists are my preferred method because it’s a way to save your search query so that it’s easy to add a long search query in the future.
When you open the search window, in the upper right there is a dropdown menu labeled Word list. Change this to Lemmas
and you’ll see the WordWheel has a list of words that are combined with a part of
speech like _adj and _adv. I’d encourage you to scroll through the top 100 most
frequent lemmas, so that you’re familiar with how parts of speech can be added.
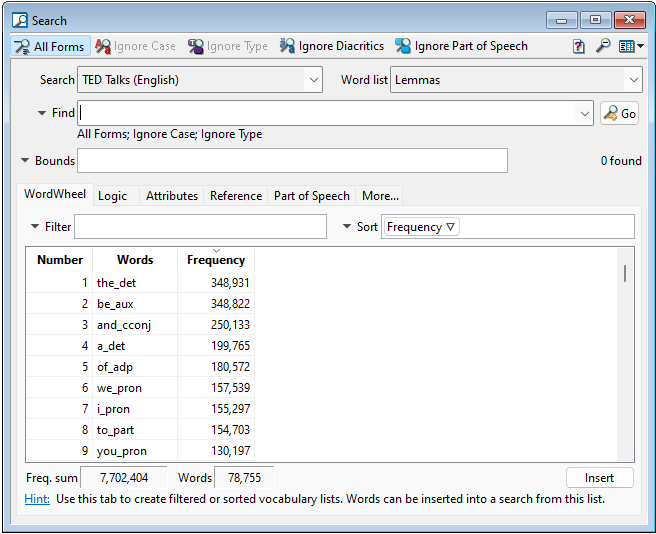
After that, we can type in each word into the search bar, separated by a +, which is the symbol for ‘or’ logic. This logic lets us look for multiple words at the same time. Here’s a small video of adding words into the search bar:
After we’ve opened the search results window, we can open the Hit Concentration
report, which will show us a more detailed table of our search results. You can
navigate to it by going to Analyze > Search Results Reports > Hit Concentration.
Step #4: Choosing the Text Best for You
You’ll notice something immediately: the hits and unique columns are all zeros! Why is that? When we did a search for these words in the Lemma
wordlist, we’re actually looking for the metadata behind the real words. Think of
the data include_verb being attached to the word including. It’s not readable,
but it was added to the word to allow us to do such searches.
Because of that, none of the words are actually considered “hits.” However, they are considered “subwords,” so we should look at the Hits (subwords) and Unique (subwords) columns on the right side of the table. I like to sort the Unique (subwords) from highest to lowest because that will show me a list of the TED talks that not only contain a lot of the search results, but it also tells me which talks have ALL of the words I searched for. Since I typed in ten words, I’d expect to see the number 10 in this column. Below I have a table of some of the best TED talks with the vocabulary:
| Citation | Unique Vocabulary | Vocabulary Frequency | Total Words |
|---|---|---|---|
| 2020 March, Seth Berkley | 10 | 94 | 11,554 |
| 2019 December, Christiana Figueres and Chris Anderson | 10 | 87 | 10,160 |
| 2006 September, Steven Levitt | 10 | 20 | 4,176 |
| 2019 December, Lorna Davis | 9 | 32 | 2,068 |
| 2009 April, Shai Agassi | 9 | 24 | 3,539 |
| 2015 October, Emilie Wapnick | 9 | 23 | 1,844 |
The first row indicates that Seth Berkley uses all ten search words in his talk, and he uses those ten words a total of 94 times. However, his overall talk is over 10,000 words long! That might not be as beneficial for a language learner trying to learn these words, but perhaps Emilie Wapnick’s 2015 TED talk would be a better fit.
And there you have it! That’s how you can find articles with specific vocabulary lists. If you try this method for your language learning or teaching, let us know at wordcruncher@byu.edu or post a comment on our Twitter or Facebook.