Type to Token Ratio Data
When someone swears a lot, people tend to think that person's vocabulary is limited. Linguists would call this a low type-to-token ratio (TTR). Types are the number of unique words a text (or speech) has, and tokens are the number of total words there are. The higher the ratio, the larger the vocabulary.
For example, Brandon Sanderson’s The Way of Kings has a TTR of 0.04 because Sanderson uses about 15,000 unique words over a 380,000-word book.
J.K. Rowling’s Harry Potter series has a TTR of 0.023 because Rowling uses about 25,500 unique words over a 1-million-word series.
By using Type-To-Token Ratio data, you can assign a number to the richness of the vocabulary of an author!
Calculating TTR
Type-to-token ratio data is calculated when the phrase compare report is generated, but you won't see it because type-to-token data can be several millions of rows long, especially if you choose to export the segments report.
Windows has a limit of how many rows it can display, so we’ve chosen to limit this report to a CSV or TXT file, which can be processed by other programs including our Type to Token Visualizer web tool.
Export to a CSV or TXT file
- Run the Phrase Compare report on a book.
- Click on the
Save resultsdropdown menu at the bottom. - Select Type-to-Token Ratio files and then select the segments or levels report.
- Provide a file name and click Save.
- If you select the levels report, you’ll get a message on whether you want the summary report or the full report.
Segments and Levels
There are 2 reports for type-to-token ratio data: segments and levels.
The segments report provides a detailed TTR report from word-to-word. Points of significance within a text can be identified down to the word level. Segment lengths are determined by your input within the Words in TTR segment input box next to the Phrase length input box.
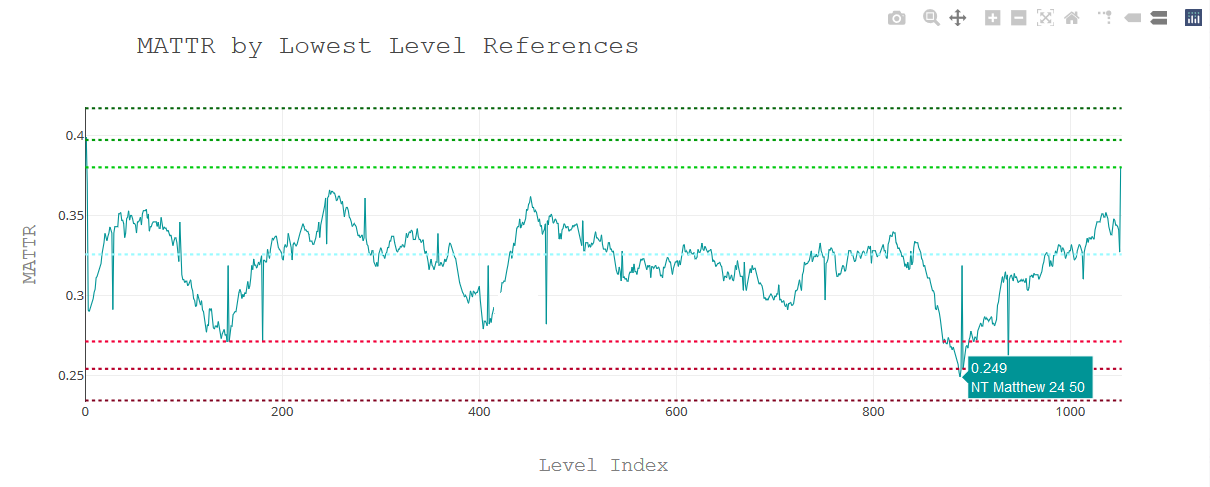
The levels report provides a summarized TTR report for each reference level of the book. Rather than looking at changes in the MATTR (Moving Average Type to Token Ratio) from word to word, this provides the MATTR for each reference level. For example, you could view the MATTR of Matthew, Mark, Luke, and John, or you could view the MATTR of Matthew 1, Matthew 2, Matthew 3, or you could even view the MATTR of Matthew 1:1, Matthew 1:2, Matthew 1:3, etc. It just depends on what you want to define as an individual “text.”
When outputing the levels report, you will be prompted if you want the summarized report or the complete report. The summarized report leaves out the lowest level references, which in most cases would be the paragraph/verse/sentence level depending on the book structure.
For a better understanding of the type-to-token data in these reports, see this PDF.